Container Virtualisierung V1.8 (c) Stor IT Back 2025
Zwei wichtige Vertreter der Container Virtualisierung sind Docker und
LXC (Linux Container). Aber was sind Container eigentlich?
Der Container nutzt einfach das schon laufende Host-Betriebssystem des Hypervisors mit. Der Container läuft als einzelner Prozess auf dem Host. Sie können es sich als eine
Applikation vorstellen, die aber gegenüber dem Betriebssystem abgeschottet ist. In einem Container muss also immer eine Applikation
(das kann aber wie ein komplettes Betriebssystem aussehen) laufen. Wird diese Applikation oder die Applikationen (es können auch mehere in einem Container sein) beendet, dann
beendet sich auch der Container. Der Container nutzt Teile des Kernels des Hosts einfach mit, daher ist er Ressourcen-schonender als eine virtuelle Maschine.
In der klassischen Virtualisierung wird ein komplettes Betriebssystem (die VM) auf
einem anderen Betriebssystem (Host, Hypervisor) gestartet. Das verbraucht sehr viele Ressourcen, da ja ein zweites komplettes Betriebssystem mit allen
Prozessen und einem eigenen Kernel laufen muss. Weiterhin braucht eine VM deutlich mehr Speicherplatz auf Festplatten, neben RAM und CPU.
Eine bildliche Darstellung von Server Virtualisierung (wie zum Beispiel VMware ESXi oder Microsoft Hyper-V) und Container (Docker oder LXC Linux Container) verdeutlicht die Unterschiede:
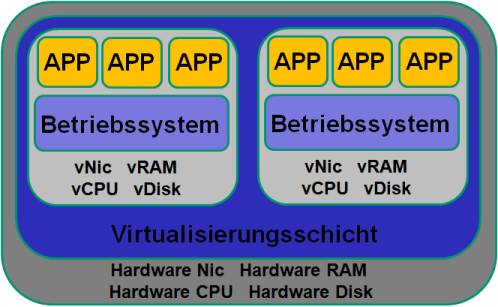

Bei einem Container läuft auf einem Betriebssystem die Docker Engine (Beispiel bei der Docker Software) und darauf die Container. Der Container hat keine virtuelle Hardware und auch kein eigenes Betriebssystem, bzw. nur einen kleinen Teil des Betriebssystems. Er nutzt Hardware und Kernel vom Host OS mit. Aber was bedeutet dies für die Kompatibilität? Der große Vorteil von Containern soll ja die flexible Nutzung auf unterschiedlichen Systemen sein, ohne groß etwas anpassen zu müssen. Nehmen wir einmal an, wir hätten einen Container auf einem Linux-System entwickelt, eine Webapplikation auf einem Debian System. Nun möchten wir diesen Container auf einem Windows System, ebenfalls unter Docker starten. Dafür wird auf Windows Hyper-V benötigt, also die Server Virtualisierung von Microsoft. Dort wird ein Linux gestartet, ab da wird alles ganz einfach ... Aber ich kann ja auch einen Windows Container (ein Container, der Windows als Basis hat) erstellen. Die läuft dann in Microsoft Windows Container, die Linux Container in Docker for Windows.
LXC findet man zum Beispiel in Proxmox VE als
einfach zu bedienende Alternative zu virtuellen Maschinen. Bei Docker ist dies Kubernetes (siehe unten) als Anwendung für die komfortable Nutzung und Bedienung.
Fangen wir erst Mal mit den Gemeinsamkeiten an. Beide nutzen den Kernel des Hosts mit und werden durch Kernelnamensräume (Linux Namespaces) und cgroups voneinander und vom
Host getrennt. Sie nutzen eigene Prozesse auf dem Host und stellen eine erweiterte chroot (change root) Umgebung zur Verfügung. Früher nutzten sogar beide Verfahren die
LXC Schnittstelle im Kernel.
Ganz grundsätzlich sieht ein LXC Container mehr wie eine virtuelle Maschine (VM) aus. Auf den ersten Blick kann man kaum Unterschiede erkennen. Es können Applikationen installiert werden und
das mit den gleichen Tools wie auf einer VM. Die fertigen Templates beinhalten das Betriebssystem und die Anwendung. Also zum Beispiel ein Debian 12 mit Wordpress. Dort ist
alles enthalten von Datenbank bis Webserver.
Bei Docker (also zum Beispiel im Docker Hub) gibt es auch Wordpress, dort besteht (bzw. kann bestehen) das Image aber aus verschiedenen Layern, also zum Beispiel der Datenbank und dem
Webserver. Diese Layer können variieren und dies ist ein großer Vorteil, wenn man sich selbst einen Docker Container bauen möchte. Man kann also die benötigten Layer kombinieren
und sich dann einen fertigen Container erstellen. Alle diese Layer findet man im Docker Hub zum Download.
Das ist aber auch das größte Problem, man kann schnell die Kontrolle verlieren. Wurde zum Beispiel ein Baustein meines eigenen Containers verändert (zum Beispiel ein Security-Update), dann
kann dies die Funktion meiner weiteren Bausteine im Container beeinflussen.
Beim LXC Container habe ich die volle Kontrolle über alle Komponenten und Bausteine, muss sie aber auch selbst zusammensetzen. Aber auch bei LXC bekommen ich sehr viele fertige
Container, von Nextcloud über Owncloud und Joomla bis Wordpress. Und auch Grundsysteme wie Tomcat, LAMP oder einem Domain Controller auf Linux. Die einzelnen LXC Container
sind immer abgeschlossen und können nicht aufeinander aufbauen. Aber sie können jederzeit erweitert werden, also das LAMP zu einem eigenen Wordpress, ohne die Wordpress Vorlage
zu nutzen.
Auch das Update eines Containers ist bei Docker und LXC grundsätzlich unterschiedlich. Bei Docker wird der Container quasi komplett neu aus dem Repository herunter geladen und damit eine neue
Version der Software genutzt. Die eigentlichen Nutzdaten müssen hierbei auf internen Platten des Host-Systems liegen. Liegt zum Beispiel die Konfiguration im Container, dann wird sie beim
Update ersetzt.
Im LXC Container wird das Update einfach wie bei einer virtuellen oder physikalischen Maschine durchgeführt. Also bei Debian mit apt update und dann apt upgrade. Wichtig ist beim LXC nie zu vergessen,
das ja der Kernel des Hosts genutzt wird. Bei Version-Upgrades sollte man also genau schauen, ob der Container später noch läuft, oder der Kernel inkompatibel zum Rest-System wird.
Die Konfiguration und Anpassung von Docker-Containern mit der Command-Line ist nicht besonders komfortabel. Weiterhin bringt Docker keine Funktionen zum Management der Umgebung (Server, Cluster, Überwachung) mit.
Kubernetes ermöglicht genau dies und vieles mehr, alles von der Bereitstellung, der Verwaltung und Überwachungen einer Container Umgebung bis zur Anpassung der Hardware-Nutzung.
Ein Kubernetes-Cluster besteht aus verschiedenen Compute-Nodes, auf welchem die Container ausgeführt werden.
Die kleinsten Einheiten in einem Kubernetes-Cluster sind die Pods, die im Normalfall eine Applikation enthalten. Diese Pods können aus einem Container, aber auch aus mehreren Containern bestehen.
Auf den Compute-Nodes laufen Agenten, die diese Pods überwachen und bei einem Ausfall diese auch wieder auf anderen Nodes starten können.
Was enthält Kubernetes an Funktionen?
- Einen Scheduler zur Verteilung der Pods bzw. Container auf den Nodes.
- Dynamische Allokation von zusätzlichen Compute-Nodes aufgrund von Laständerungen.
- Überwachung von Pods / Containern und ein möglicher Neustart bei Bedarf.
- Alle Pods und Services werden im Cluster intern registriert und verwaltet.
- Rolling Upgrades von Pods.
- Storage Verwaltung von Storage Lösungen wie AWS EBS, S3, Ceph, NFS und iSCSI.
Kubernetes ist also eine Management-Anwendung für Docker Container. Je größer und umfangreicher eine Umgebung wird, desto wichtiger werden Lösungen wie Kubernetes. Einzelne Container
lassen sich aber auch ohne Kubernetes verwalten. Der Aufwand für Kubernetes in kleinen Umgebungen wäre deutlich zu groß.
Docker basiert auf verschiedenen Linux-Technologien wie zum Beispiel Cgroups und Namespaces. Mit einer Programmierschnittstelle libcontainer, LXC (Linux Containers) zur Prozess-Isolation und
dem Overlay-Dateisystem AuFS (oder auch btrfs) stellt Docker die Container zur Verfügung. Weitere Begriffe:
Image
Das Image ist das Speicherabbild eines Containers. Es besteht aus mehreren Layern, die schreibgeschützt sind. Das Image muss nicht installiert werden,
ein einfaches Kopieren reicht für die Installation aus. Das Image kann auch in Repositories gespeichert und von dort verteilt werden.
Container
Von einem Container spricht man, wenn ein Image aktiv ausgeführt wird. Ist quasi mit einer laufenden virtuellen Maschine vergleichbar. Der Container kann gestoppt werden bzw.
wird nach Ablauf des Programms automatisch gestoppt.
libcontainer
Dies ist die Schnittstelle zu allen Grundfunktionen eines Docker Containers
libswarm
Dies ist die Schnittstelle zur Steuerung von Docker Containern
libchan
Ermöglicht eine einfache Kommunikation zwischen Prozessen und Prozessteilen von Docker
LXC
LXC ist die Basis für Container, es stellt eine Programmbibliothek, APIs, Containervorlagen und Werkzeuge zur Kontrolle der Container. Weiterhin ermöglicht LXC die Container
unter anderen Usern als root zu starten. Eine wichtige Sicherheitsfunktion. Container können damit nicht mehr so einfach auf das Hostsystem zugreifen.
cgroups
Die cgroups sind für die Ressourcenverwaltung der Container zuständig. Sie begrenzen den Speicher, den Durchsatz im Netzwerk und auf die Festplatten.
Layer
Ein Layer ist ein Teil eines Images, der Befehle oder Dateien enthält, die einem Image hinzugefügt wurden. Damit lassen sich verschiedene Container aus einem einzelnen Image erstellen.
Dockerfile
Das Dockerfile ist eine Textdatei, die Befehle enthält, die bei der Ausführung des Containers abgearbeitet werden. Für jeden Befehl in dem Dockerfile wird ein Layer angelegt.
Repository
Ein Repository enthält verschiedene Images, die zum Beispiel unterschiedliche Versionen oder Entwicklungsschritte sein können
Die größte Akzeptanz finden Container bei Software-Entwicklern, die verschiedene Versionen ihrer Software auf unterschiedlichen Systemen entwickeln und
testen müssen. Was sind dort die konkreten Vorteile der Container? Die Entwickler können auf einem Basis-System (dem Docker-Host) verschiedene Versionen von
Betriebssystemen mit verschiedenen Versionen ihrer Software kombinieren und dann testen. Da die Container aus einzelnen Layern aufgebaut sind, lassen sie sich einfach
und schnell kombinieren und starten.
Aber nicht nur bei der Software-Entwicklung spielen Container eine immer größere Rolle, auch bei Administratoren in Unternehmen. In Containern können einfach und
schnell Anwendungen den Nutzern zur Verfügung gestellt werden, für die eigentlich keine Betriebssysteme vorhanden sind oder Voraussetzungen nicht erfüllt sind. Aber auch
ein Update der Anwendung wird deutlich einfacher. Der Container wird ja aus einem Image gestartet und das kann für verschiedene Nutzer immer das gleiche sein (siehe das Beispiel
mit dem Webserver oben). Das Update muss also nur auf dem einen "golden" Image durchgeführt werden und nach einem Neustart der Container haben alle Anwender die neue Version. Sie stellen
einen Fehler in der neuen Applikation fest, aber haben es schon an alle Nutzer verteilt? Kein Problem, das alte Image wieder herstellen und alle Container neu starten. Mit
einer klassischen Softwareverteilung ist das nicht möglich, bzw. mit deutlich mehr Aufwand.
Wie können Container einfach und schnell gesichert werden? Die Basis dafür haben Sie schon kennengelernt. Wenn ein Container läuft, dann kann er mit dem Befehl docker commit im aktuellen
Zustand auf ein neues Image kopiert werden. Damit haben wir eine schnelle und einfache Sicherung von laufenden Containern. Eines ist dabei aber zu beachten: Die Daten in dem Container
müssen konsistent sein. Was bedeutet dies? Wenn zum Beispiel eine Datenbank in dem Container läuft und die Sicherung wird bei laufender Datenbank über Transaktionen hinweg
durchgeführt, so lässt sich entweder die Datenbank aus der Sicherung nicht starten oder die Daten sind nicht konsistent. In beiden Fällen ist das Backup nicht brauchbar. Dafür gibt es
aber eine einfache Lösung: docker commit -p pausiert den Container für den commit Befehl, also für unsere Datenbank.
Damit ist eine einfache Datensicherung möglich, aber wie läuft die Recovery? Eigentlich noch einfacher. Wichtig ist natürlich vorher die Sicherung auf einen anderen Server und andere
Plattensysteme zu verschieben. Das kann ganz Docker-Konform mit einem privaten Docker Repository erledigt werden. Mit dem Befehlt docker push kann das Image der Datensicherung verschoben
werden. Aber kommen wir zur Recovery, das Image liegt auf einem Repository und von dort kann der Container mit docker load auf den gleichen oder einen anderen Docker Host geladen
und mit docker run gleich gestartet werden. Viel einfacher geht es nicht und Sie benötigen nicht einmal eine Backup-Software.
Kann der Ablauf noch verbessert werden oder wo liegen die Nachteile? Nehmen wir einmal an, wir starten viele Container aus dem gleichen Image. Somit ist der Unterschied zwischen den
Containern nur der obere Read Write Layer. Die restlichen Layer sind ja immer gleich. Also warum nicht nur den oberen Layer sichern? Dies spart Plattenplatz in der Sicherung und
Zeit beim Backup und auch beim Restore.
Was natürlich auch immer geht, aber nicht die eleganteste Lösung ist: Einfach eine Sicherung innerhalb des Containers erstellen und per
NFS, SMB oder Backup-Client außerhalb des
Containers sichern. Also so, als wäre man auf einer physikalischen Maschine.
Was sind Container in der EDV?
Container sind leichtgewichtige, isolierte Umgebungen, in denen Anwendungen inklusive ihrer Abhängigkeiten laufen. Anders als virtuelle Maschinen benötigen Container kein vollständiges Betriebssystem, sondern teilen sich den Kernel des Hostsystems. Dadurch starten sie in Sekunden und verbrauchen deutlich weniger Ressourcen. Container eignen sich besonders für Microservices, Testumgebungen und skalierbare Anwendungen.
Worin unterscheiden sich Container von virtuellen Maschinen (VMs)?
VMs beinhalten ein vollständiges Betriebssystem und sind daher ressourcenintensiver. Container nutzen nur das Nötigste, was die Anwendung braucht, und teilen das Hostsystem effizient. Dadurch lassen sich auf derselben Hardware oft zehnmal mehr Container betreiben als VMs. Für Entscheider bedeutet das: geringere Infrastrukturkosten und bessere Auslastung der vorhandenen Systeme.
Was ist ein Container-Image und wie wird es erstellt?
Ein Image ist eine Vorlage, aus der Container gestartet werden. Es enthält alle benötigten Dateien, Abhängigkeiten und Konfigurationen. Administratoren definieren ein Image oft über eine einfache Textdatei (Dockerfile), die beschreibt, wie die Umgebung aufgebaut sein soll. Images sind versionierbar, wodurch Rollbacks und reproduzierbare Deployments leicht möglich sind.
Wie werden Container im produktiven Umfeld orchestriert?
Für produktive Umgebungen reicht das Verwalten einzelner Container oft nicht aus. Hier kommen Orchestrierungsplattformen wie Kubernetes, Docker Swarm oder Nomad zum Einsatz. Sie kümmern sich automatisch um Skalierung, Ausfallsicherheit, Updates und das Verteilen der Container auf mehrere Server. Das entlastet Administratoren und gewährleistet hohe Verfügbarkeit der Anwendungen.
Welche Sicherheitsaspekte müssen bei Containern beachtet werden?
Container sind leichter isoliert als klassische Prozesse, aber nicht so stark wie VMs. Sicherheitsrisiken liegen häufig in fehlerhaften Images, unsicheren Konfigurationen oder schlecht gepflegten Basis-Images. Best Practices sind u. a.: minimale Images verwenden, Zugriffsrechte einschränken, Secrets nicht im Container speichern und Images regelmäßig scannen. Für Entscheider ist wichtig: Sicherheit ist kein Nebenprodukt – Container brauchen eine klare Governance.
Welche Anforderungen stellt Container-Technologie an die Infrastruktur?
Container benötigen ein performantes Hostsystem, stabile Netzwerke und im produktiven Umfeld verteilte Speicherlösungen. CPUs und RAM sind weniger kritisch als bei VMs, da Container leichter sind. Wichtig ist die Stabilität des Hostkernels sowie Monitoring- und Logging-Lösungen. Wer Cluster aufbaut (z. B. Kubernetes), muss zusätzlich Lastausgleich, redundante Control-Planes und ausreichend Storage berücksichtigen.
Wofür eignen sich Container besonders gut?
Container sind ideal für Microservices, APIs, Webanwendungen, CI/CD-Pipelines und automatisierte Tests. Sie ermöglichen schnelle Iterationen, da Entwickler Änderungen ohne großen Aufwand testen können. Auch batchartige Prozesse wie Datenverarbeitung oder Hintergrundjobs profitieren davon. Unternehmen nutzen Container zudem, um Anwendungen cloudunabhängig zu deployen oder hybride Architekturen aufzubauen.
Welche Einschränkungen oder Herausforderungen gibt es?
Nicht jede Anwendung ist sofort containerfähig – besonders solche, die tief ins Betriebssystem eingreifen oder Hardwarezugriffe benötigen. Persistent Storage ist komplexer, da Container von Natur aus kurzlebig sind. Auch das Monitoring und Logging müssen angepasst werden, um Containerflotten effizient zu verwalten. Dennoch können diese Herausforderungen mit modernen Tools meist gut gelöst werden.