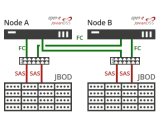
ZFS was ist das eigentlich?
Kurz gesagt ein transaktionales Dateisystem, von Sun Microsystems (die mit Solaris ...) entwickelt und ursprünglich als
Zettabyte File System bezeichnet. Das Zettabyte steht hierbei für die große maximale Dateisystemgröße. Es ist auch eine integrierte RAID-Funktion
enthalten, sowie ein Volume-Magement und ein prüfsummenbasierter Schutz vor Fehlern (gegen Übertragungs- und Festplattenfehler).

Linux im Unternehmen - ZFS Pool erstellen mit verschiedenen RAID-Leveln
Im Video angesprochene Einstellungen und Befehle als Copy & Paste:
Installation von ZFS auf Debian: apt install zfsutils-linux Achtung bei dem Anlegen des Pools: Die angegebenen Devices (z.B. /dev/sda) werden komplett gelöscht!!! Genau auf die richtigen Device-Namen achten. Es erfolgt KEINE Rückfrage! Der Parameter -f (= force) löscht auch HDD / SDD mit vorhandenen Daten (Partitionen)! Anlegen Pool JBOD / Single Disk: zpool create -f test1 /dev/xxx Anlegen Pool RAID 1: zpool create -f test1 mirror /dev/xxx /dev/yyyy Anlegen Pool RAID 10: zpool create -f test1 mirror /dev/www /dev/xxx mirror /dev/yyy /dev/zzz Anlegen Pool RAID 5: zpool create -f test1 raidz /dev/wwww /dev/xxx /dev/yyy /dev/zzz Anlegen Pool RAID 6: zpool create -f test1 raidz2 /dev/wwww /dev/xxx /dev/yyy /dev/zzz Anlegen Pool RAID 5 mit Hot Spare zpool create -f test1 draid1:1s /dev/wwww /dev/xxx /dev/yyy /dev/zzz Hinzufügen von einer Log SSD und Cache SSD zu einem Pool: zpool add -f test1 log /dev/aaa cache /dev/bbb Physikalische Sektorengröße auslesen: lsblk -o NAME,PHY-SEC Auslesen ashift aus einem Pool: zpool get ashift test Anmerkung: Kann nur beim Anlgen des Pools vorgegeben werden (-o ashift=12 beim zpool create) Berechnung ashift: PHY-SEC = 2 hoch ashift

Linux im Unternehmen - ZFS Snapshots
Im Video angesprochene Einstellungen und Befehle als Copy & Paste:
zpool list zfs list zfs create test1/prod dd if=/dev/random of=out1 bs=1M count=100 dd if=/dev/random of=out2 bs=1M count=120 dd if=/dev/random of=out3 bs=1M count=140 zfs snapshot test/prod@snap1 zfs snapshot test/prod@snap2 zfs snapshot test/prod@snap3 zfs list -t snapshot mkdir /snap mkdir /snap/snap1 mkdir /snap/snap2 mkdir /snap/snap3 mount -t zfs test1/prod/@snap1 /snap/snap1 mount -t zfs test1/prod/@snap2 /snap/snap2 mount -t zfs test1/prod/@snap3 /snap/snap3 zfs diff test1/prod@snap1 zfs diff test1/prod@snap2 zfs diff test1/prod@snap3 zfs rollback test1/prod@snap3 umount/snap/snap1 zfs destroy test1/prod@snap1 zfs destroy -v test1/prod@snap1

Linux im Unternehmen - ZFS Replikationen
Im Video angesprochene Einstellungen und Befehle als Copy & Paste:
zpool list zfs list zfs snapshot test/prod@repli zfs list -t snapshot zfs diff test1/prod@repli zfs send -v test1/prod@repli | zfs recv backup/prod zfs diff backup/prod@repli zfs send -v test1/prod@repli > repli.zfs (in eine Datei) zfs send -v test1/prod@repli | ssh root@backupserver zfs recv backup/prod (auf einen anderen Server) Tips: zfs send -i (inkrementell)
Wie könnte man die Replikationen optimieren?
1. Die Snapshots werden individuell erstellt. Also nicht alle mit @repli, sondern mit @timestamp
2. Die Replikation erfolgt dann inkrementell (mit -i)
3. Die Snapshot sind auch auf dem Zielsystem oder Pool zugreifbar
4. Aus den replizierten Snapshots auf ein anderes System wird ein Backup
5. Der Snapshot alleine ist aber nie ein Backup!