Server-Virtualisierung - Storage V1.8 (c) Stor IT Back 2024
Der Server bei der Server-Virtualisierung ist nur ein Baustein der Lösung. Der zweite und fast noch wichtigere Baustein ist die Storage-Lösung. Es entscheidet über Performance und Verfügbarkeit. Beim Server ist die Auswahl recht einfach, Menge an RAM und passende CPUs sind die Basis-Entscheidungen. Redundante Netzteile und Lüfter sind Standard, Performance und Verfügbarkeit wird durch die Anzahl der Server verändert. Und selbst wenn die Performance nach einer gewissen Zeit nicht mehr ausreichend für die Anzahl der virtuellen Maschinen ist, dann nimmt man einfach einen weiteren Server hinzu. Durch Features wie Online Migration / VMotion, Hochverfügbarkeit / HA und Fault Tolerance kann bei entsprechender Dimensionierung zusätzlich ein Serverausfall durchaus verkraftet werden.
Aber beim Storage sieht vieles anders aus. Einfach ein zweites Storage, wenn die Performance nicht mehr ausreichend ist? Sicherlich der falsche Weg. Einfach ein weiteres Storage, wenn der Platz zu knapp wird? Auch nicht der beste Weg, ein erweiterbares Storage-System in der Erstanschaffung wäre effektiver und kostengünstiger gewesen. Aber ist Performance und Kapazität schon alles? Auch die Verfügbarkeit ist ein wichtiger Baustein. Beim Server war es einfach, einen weiteren Server integrieren, der im Fall eines Falles die Aufgaben übernehmen kann. Aber wie geht das beim Storage? So einfach auf jeden Fall nicht, oder doch? Die Daten müssen ja auf beiden Storage-Systemen vorhanden sein und zwar absolut identisch. Sollte das eine Storage ausfallen, dann muss auf dem zweiten System exakt der gleiche Datenbestand bestehen, bis auf das letzte Bit. Das erreicht man mit einer Replikation (Spiegelung) zwischen den Storage-Systemen, das kann aber nicht jedes Storage.
Ein neuer Ansatz sind Hyperconverged Systems, hier werden Rechenleistung (der eigentliche Server) und Speicherplatz (das eigentliche Storage) in konventionellen Servern zusammengefasst. Aber wie werden bei lokalem Speicher in einem Hypervisor Features wie HA und VMotion möglich? Der lokale Speicher wird auf die weiteren Hyperconverged Systems repliziert und allen beteiligten Hypervisoren zur Verfügung gestellt.
Dies ist die neuste Entwicklung in der Storage-Virtualisierung, hauptsächlich bei virtuellen Umgebungen.
Eigentlich ist sowohl die In-Band, wie auch die Out-of-Band Virtualisierung
eine Software-Virtualisierung, also soweit nichts Neues. Aber das Software defined Storage zeigt ganz neue
Methoden. So hat VMware zum Beispiel das vSAN entwickelt. Auf einem ESXi Server wird ein Plattenpool, bestehend aus SSDs und SAS- und/oder NL-SAS-Platten, gebildet.
Dieser Pool wird über einen Cluster von ESXi Servern (mindestens 3 Server) gemeinsam gebildet und verteilt. Die Daten werden über 2 oder mehr ESXi Server
gespiegelt. Sollte jetzt eine Festplatte (oder SSD) ausfallen, so werden die gespiegelten Daten neu verteilt. Dies Verfahren ist ähnlich einem RAID 1,
spiegelt die Daten aber zwischen Servern, ein Software-RAID.
Die Verteilung der Daten erfolgt über Ethernet (mindestens 10 Gbit/s), die Latenzzeiten sollte genau beachtet werden. Ein
Nachteil kann sich bei großen Datenmengen pro Server ergeben. Sollte ein Server ausfallen, so müssen große Datenmengen verlagert bzw. neu generiert werden.
Eine extreme Belastung der Server, wenn dies in der Haupt-Online-Zeit durchgeführt werden muss.
Ein Storage-System an sich ist meist schon recht redundant ausgelegt. Redundante Netzteile und Lüfter sind der
normale Standard. Auch die Festplatten werden über den passenden RAID-Level abgesichert, dort kann eine Platte ausfallen,
die Hot Spare übernimmt sofort. Oder beim RAID 6 können sogar zwei Platten ausfallen.
Storage-Systeme, gerade für die
Virtualisierung, gehen noch einen Schritt weiter. Die RAID-Controller sind auch doppelt vorhanden. Was bedeutet dies? Man kann
es sich wie zwei komplette Server in einem Gehäuse vorstellen. Es arbeiten zwei getrennte Systeme
(eigene CPU, eigener Speicher, eigenes Board, eigene BBU) getrennt voneinander, aber jeder weiß immer genau, was der andere gerade tut.
Zu jedem Zeitpunkt kann der andere Controller die Arbeit des Partners übernehmen und das auch noch transparent für
die Server. Also ist ein Storage-System bei der richtigen Auslegung schon mal redundanter als ein Server.
Aber gegen äußere Einflüsse, wie Feuer und Wasser, kann auch diese Redundanz nichts ausrichten.
Dort hilft nur die Replikation der Daten an einen zweiten Brandabschnitt (und "zweiten Wasserabschnitt").
Warum und wann ist diese Replikation wichtig? Nehmen wir einmal an, dass das gesamte System verbrannt ist und die Daten müssen
aus der Datensicherung wiederhergestellt werden. Dies kann je nach Datenmenge schnell mal ein paar Tage dauern, ein Tag ist
auf jeden Fall immer weg.
Und da kommt die Replikation zum Zuge. Umschaltung auf das zweite System, Ersatzserver starten (die
hoffentlich auch am zweiten Standort stehen) und das System läuft wieder. Eventuell mit geringerer Leistung, aber selbst
im K-Fall ist man in wenigen Minuten (wenn man es geübt hat) wieder Online.
Ob diese Replikation wirklich notwendig ist, hängt immer von den Umständen des Unternehmens ab. Es sind auch Varianten mit
asynchroner Replikation möglich. Dies kann zum Beispiel auch von einer Software-Lösung ermöglicht werden. Eine Variante ist Backup and Replication
von Veeam. Dort können einzelne virtuelle Maschinen auf einen anderen Speicher zeitabhängig repliziert werden. Eine kostengünstige Lösung,
die auch noch unabhängig von den Speichersystemen ist.
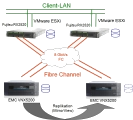
Wie schon beschrieben gibt es verschiedene Möglichkeiten, eine Virtualisierungslösung aufzubauen. Die einfachste Variante sind zwei Server und ein Storage-System. In diesem Beispiel besitzt das Storage System (Dell EMC Unity) zwei RAID Controller, daher muss jeder Server auch mit zwei Kanälen an das Storage angeschlossen werden (jeweils ein Kanal pro Controller bzw. Service Prozessor der Unity). Sollte jetzt ein Kanal im Server, ein LWL Kabel oder ein Controller im Storage System ausfallen, so kann die Multipathing-Software (die bei VMware ESXi, Hyper-V, XEN und KVM enthalten ist) automatisch auf den verbleibenden Kanal umschalten. Die Daten bleiben weiter für die virtuellen Maschinen verfügbar.
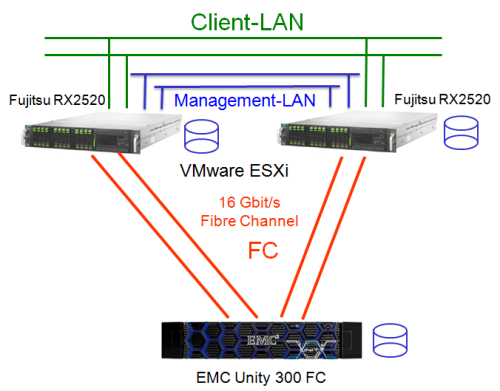
In diesem Beispiel sind die Server mit Fibre Channel angebunden und zwar direkt an das Storage ohne Switch. Dies geht in dem Beispiel, weil das Storage Systeme über
2 Kanäle verfügt und damit 2 Server direkt angeschlossen werden können. Werden mehr als 2 Server benötigt, dann wird bei diesem Storage ein
Fibre Channel Switch oder zusätzliche Host-Karten pro Service Prozessor benötigt. Um genauer zu sein, man benötigt dann 2 Fibre Channel Switche,
ebenfalls wegen der Redundanz. Sollte ansonsten der einzige vorhandene Switch ausfallen, dann verlieren alle Server die Verbindung zum Storage, alle virtuellen Maschinen fallen aus.
Neben Fibre Channel kann auch SAS als Anschlussmedium genutzt werden. Einziger Nachteil von SAS ist die geringere Entfernung zwischen Server und Storage. Auch ein direkter
Anschluss ist möglich (der Normalfall bei SAS), ebenso ein SAS Switch, wenn mehrere Server angeschlossen werden sollen. Eine Replikation über SAS ist kaum
sinnvoll machbar, da die Entfernung einfach zu gering für einen zweiten Brandabschnitt ist.
Der Aufbau mit den Servern bleibt auch in diesem Fall gleich, es werden nur aus den 2 jetzt 4 Server. Dies ist aber unerheblich für die Replikation. Nur sollten die Server auch an beide Brandabschnitte verteilt werden. Wichtig sind jetzt aber die beiden Storage-Systeme. Sie replizieren die Daten entweder synchron oder asynchron zwischen den Systemen. In den meisten Fällen können beide Storage-Systeme aktiv Daten anbieten, allerdings nicht die gleichen LUNs.
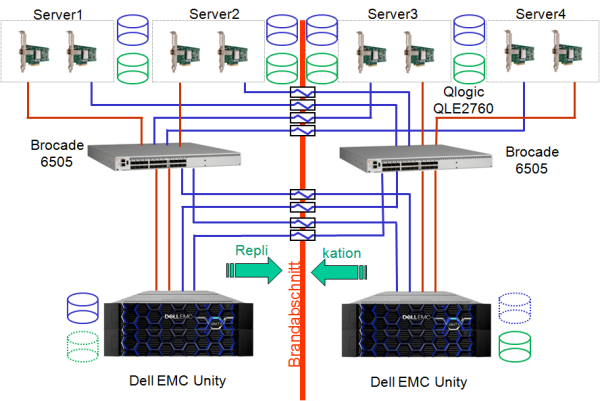
Also das eine Storage
ist aktiv für die LUN 1 und das andere dann für die LUN 2. Sollte jetzt das eine System ausfallen, so muss die bisher nicht
aktive LUN dann für die Server aktiv geschaltet werden. Damit können die Server auf diese LUN zugreifen. War es eine synchrone Spiegelung, dann
kann ohne Datenverlust direkt weiter gearbeitet werden, meist nach einem manuellen Eingriff. Damit kann
der Ausfall eines kompletten Brandabschnittes abgefangen werden. Das ist immer dann sinnvoll, wenn ein längerer Ausfall der Systeme auch
bei größeren Störungen nicht akzeptabel ist. Oder wenn so große Datenmengen vorhanden sind, das eine Recovery über Bänder
oder Disksysteme nicht
in einem akzeptablen Zeitrahmen möglich ist. Ein einfaches Beispiel: Wenn Sie maximal mit 200 MB/s Daten auf ein System bringen können, sie nutzen aber 40 TB,
dann werden im Idealfalle über 55 Stunden benötigt. In der Praxis wird eine Recovery sicherlich deutlich über eine Woche dauern, da eine Sicherung
bei dieser Menge nur noch inkrementell möglich ist. Mit einer Replikation sind die Daten innerhalb von wenigen Minuten wieder nutzbar.
Wer braucht eine Replikation? Eigentlich alle, die keinen auch nur so geringen Datenverlust selbst im K-Fall akzeptieren können und bei denen selbst kurze
Ausfälle einen hohen Schaden verursachen. Was muss neben der Replikation sonst noch an Basisvorgaben erfüllt sein? Die Systeme sollten an zwei
Brandabschnitten verteilt aufgebaut sein. Viele äußere Gefahren wie Brand oder Wasser lassen sich so vermeiden, das richtige Konzept einmal vorausgesetzt.
Deutlich häufiger sind Stromausfälle, die sich nur mit redundanten Einspeisungen abfangen lassen. Die Ausstattung mit einer USV pro Brandabschnitt ist dabei
trotzdem Standard.
Gerade in kleineren Umgebungen ist ein repliziertes externes Storage-System oft zu teuer und/oder zu aufwendig. Deswegen bot VMware ein internes Storage-
Replikationsverfahren (VMware vSphere Storage Appliance) an. Die Replikation wurde von einer virtuellen Maschine übernommen bzw. gesteuert und die Daten werden über LAN
zwischen den einzelnen ESX-Server hin und her repliziert. Mit dieser Lösung war auch HA (die Hochverfügbarkeitsfunktion von VMware) und VMotion möglich.
Im ersten Blick eine ideale Lösung, es werden nur die ESX-Server mit internen Platten
benötigt, eine kostengünstige und einfache Lösung. Aber der Nachteil ist: Die Performance ist stark abhängig von der Replikation.
Und da dort die Latenzzeiten über Ethernet hoch sind (im Vergleich zu FC oder SAS), wirkt sich dies auf die Schreibperformance (nur hierfür wird ja die Replikation benötigt) negativ aus.
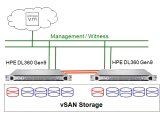
Deswegen hat VMware das VSAN entwickelt. Ein ähnlicher Aufbau, es werden in den ESXi Servern interne Platten benötigt und mindestens eine SSD für die Performance. Die Daten
werden objektbezogen auf dem Speicher abgelegt und wie ein RAID 1 über mehrere ESXi Systeme verteilt. Eine gute Performance und eine gute Sicherheit ohne
externe Storage-Systeme.
Aber nicht nur VMware bietet diese Lösung an, auch viele Hersteller von Storage-Software bieten diese Möglichkeiten, als Vorläufer der Hyperconverged Systems, an. Aber wie wird es dort gemacht? Als
erstes wird die Storage-Software (z.B. Open-E DSS v7 oder Datacore) als virtuelle Maschine auf den beiden ESXi-Servern installiert, in einer eigenen kleinen LUN.
Der restliche Speicherplatz auf den Servern wird direkt der Storage-Software zur Verfügung gestellt (z.B. als RAW-Device). Die Storage-Software baut aus dieser LUN
dann ihrer eigene virtuelle LUN und stellt diese dem ESX über iSCSI zur Verfügung. Der ESX nutzt dann diese virtuelle LUN als VMFS-Volume und darauf werden die
eigentlichen virtuellen Maschinen installiert. Aber warum zweimal durch den ESX und einmal durch die Storage-Software? Die Storage-Software kann jetzt die Änderungen
auf der virtuellen LUN direkt an den zweiten ESX (der identisch aufgebaut ist) weiterleiten (LAN-Verbindung, z.B. DRBD). Damit sind die virtuellen LUNs der Storage-Software auf allen
ESXi-Servern gleich. Über iSCSI kann jeder ESXi auf beide gespiegelten LUNs zugreifen, ein HA ist möglich, VMotion auch. Hört sich so ein wenig nach Ei und Henne an.
Was passiert wenn ein ESXi ausfallen sollte? Der Zugriff auf die iSCSI LUN auf diesem Server ist nicht mehr möglich. Je nach Storage-Software erfolgt eine
automatische oder manuelle Umschaltung auf den anderen ESX. Bei der automatischen Umschaltung kann der ESXi weiter auf die VMs zugreifen, HA wird die VMs des
anderen ausgefallenen ESX wieder neu starten.
Ideal bei kleinen Anwendungen ohne große Performance-Ansprüche. Eine hochverfügbare Lösung an zwei Brandabschnitten mit
Cluster für wenig Geld.
Der neuste Ansatz in der Server-Virtualisierung, alle namhaften Hersteller sind auf den Zug aufgesprungen.
Aber was bedeutet Hyperconverged Systems eigentlich?
Der Name setzt sich aus Hyper und Converged zusammen, also Hyper-Konvergenz. Eine konvergente Infrastruktur (in diesem Fall die Virtualisierung) vereinigt einzelne IT
Komponenten zu einer Appliance, die sich zentral verwalten lässt. Damit sollen Inkompatibilitäten vermieden und Administration und Überwachung vereinfacht werden.
Und das Vorwort Hyper deutet auf den Hypervisor hin. Also eine Zusammenfassung auf Basis des Hypervisors. Und auch genau das ist es, Rechenleistung, Speicherplatz
und Netzwerk auf einem Server.
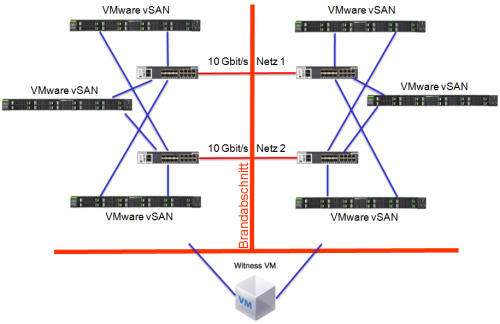
Ein Vertreter dieser Lösung ist VMware mit dem Produkt vSAN. Es ist eine eigene Lösung von VMware und nur VMware-Produkte (zur Zeit nur der ESXi) können vSAN nutzen. Es ist ein "normaler" Objekt-Speicher, läuft aber nur auf einem ESXi. Den gleichen Ansatz verfolgt Ceph mit dem gleichnamigen Produkt, jedoch ist es Open-Source und damit recht frei nutzbar. Dieser Speicher kann als eigenständige Lösung genutzt werden, also auf eigenen Ceph-Servern, aber auch auf einem Proxmox VE Server. Also wie das vSAN auf dem Host mit dabei, also auch ein Server für VMs und Storage. Das Ceph kann allerdings von vielen Produkten und Anwendungen genutzt werden.
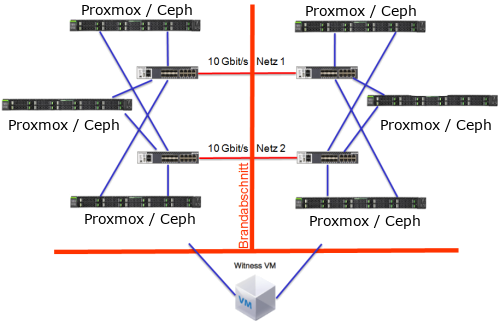
Der Aufbau ist fast identisch und hat auch recht ähnlich Voraussetzungen.
In der Praxis kommt es jedoch auf einige Details an, wie wird zum Beispiel der Transport der Daten zwischen den Speicherknoten realisiert.
Dies hat einen großen Einfluss auf die Performance des Gesamtsystems. Eine Schreiboperation wird einmal zu den lokalen Platten geleitet (dies ist extrem schnell), muss
aber wegen der Redundanz auch mindestens zu einem zweiten System und dessen Platten kommen. Erfolgt der Transport über Ethernet ohne Optimierungen, dann kann
dies gerade bei Datenbanken zu Verzögerungen führen. Ein optimiertes und exklusives Übertragungsmedium bringt also Performance. Aber wie sieht es mit der Sicherheit aus?
Es muss eine synchrone Übertragung der Daten zwischen den Knoten sichergestellt werden, das bedeutet, die virtuelle Maschine bekommt erst dann den Write-OK, wenn
die Daten an allen definierten Storage-Nodes angekommen sind. Wenn dann noch die Anzahl der Duplikate einstellbar ist und Duplikate an
verschiedenen Standorten (= Brandabschnitten) aufgestellt sein können, dann ist die Verfügbarkeit flexibel gegeben, bis zur K-Fall Vorsorge.
Kommen wir jetzt zur Erweiterung bzw. Skalierbarkeit von Hyperkonvergenten Systemen: Wird mehr Rechenleistung oder mehr Hauptspeicher benötigt, dann kann ein weiterer
Knoten dem Cluster hinzugefügt. Dabei kommt es auf den Hersteller an, ob auch Knoten ohne Speicherplatz angeboten werden. Da ist Ceph klar im Vorteil,
weder Proxmox muss einen Ceph Node besitzen, noch muss Ceph auf einem Proxmox VE Host sein.
Wird bei VMware mehr Speicherplatz benötigt, so
muss ein Knoten mit Speicherplatz dem Cluster hinzugefügt werden. Da aber der Datenschutz immer nur mit einem RAID 1 (= Spiegelung) erreicht wird,
werden dann zwei Storage-Nodes benötigt. Je nach Hersteller des Systems können wenige oder keine Redundanzen innerhalb eines Systems gegeben sein
(es wird quasi ein RAID 0 verwendet), daher sollten die Daten mindestens über 3 Systeme gespiegelt werden. Sollte bei einem einfachen Spiegel ein Knoten ausfallen,
so ist selbst bei extrem großen Datenmengen keine Redundanz mehr vorhanden. Ein Ausfall einer weiteren Platte kann zum totalen Datenverlust
führen. Eine Erweiterung kann also teuer werden, da ist die Auswahl des passenden Herstellers beim Start in der Hyper-Converged Welt extrem wichtig.
Für Virtualisierungsprojekte bieten wir die passenden Storage-Lösungen an, setzen Sie sich mit uns in Verbindung. Natürlich können Sie auch komplette Lösungen von uns bekommen. Egal zu welcher Virtualisierungssoftware, wir finden eine für Sie passende Storagelösung, ob Direct Attached, klassisch als SAN oder Hyper-Converged.