Server-Virtualisierung - Performance V1.8 (c) Stor IT Back 2025
Schon bei reinen physikalischen Systemen ohne jegliche Virtualisierung ist
eine Performance Vorhersage recht schwierig. Es spielen einige Faktoren bei der
Performance-Betrachtung eine wichtige Rolle, viele sind nur sehr schwer zu erfassen, die meisten ändern sich dynamisch.
Ein einfaches Beispiel:
Eine Datenbank zeigt eine sehr schlechte Performance,
die User beschweren sich über langsame Antwortzeiten, die Applikationen
sind wegen der schlechten Geschwindigkeit nur schwer zu bedienen.
Woran kann dies liegen?
Allgemein am Server, am Netzwerk, am Client oder an der Datenbank oder
Applikation. Die Datenbank und die Applikation
ist erfahrungsgemäß die Ursache der größten Probleme, auch Client und das Netzwerk können Einfluss nehmen.
Dann haben wir noch den Server, dieser Besteht aus CPU, Hauptspeicher und Festplattenspeicher.
Die Dimensionierung von CPU und Hauptspeicher sind bei der Virtualisierung sehr wichtig. Ein Hauptvorteil der Server-Virtualisierung ist ja gerade die bessere Ausnutzung der modernen CPUs. Aber was ist, wenn die CPU jetzt überlastet ist? Die Anwendung wird langsamer als sie sein sollte. Bei einer richtigen Überwachung durch Schwellwert-Alarme in der Virtualisierungsschicht ist dieses Problem leicht zu erkennen. Auch bei der Auslastung des Hauptspeichers bietet die Virtualisierung meist einfache und effektive Überwachungsmöglichkeiten. Gleiches muss dann auch entsprechend in den virtuellen Maschinen überwacht werden. Ist die Dimensionierung von Hauptspeicher- und CPU-Ressource für die VM ausreichend? Oder muss dort angepasst werden?
Jetzt bleibt bei dieser Betrachtung nur noch der Speicherplatz übrig. Auch dort bieten viele Virtualisierungsprodukte umfangreiche Analysewerkzeuge an. So kann z.B. die I/O Belastung einer Platte gemessen und grafisch ausgewertet werden, ebenso der Durchsatz und die I/O-Wartezeit. Wird dort ein Engpass angezeigt, so wird es aber schwierig dies zu verbessern. Bei fehlendem Hauptspeicher ist es einfach: Aufrüstung des RAMs in der physikalischen Maschine oder die Verlagerung von virtuellen Maschinen auf eine andere Hardware. Aber was kann bei Performance-Problemen im Storage-Backend geändert werden?
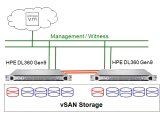
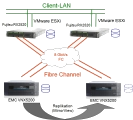
Schauen wir uns die Storage-Möglichkeiten in der virtuellen Welt einmal etwas genauer an. Die VM (virtuelle Maschine) nutzt einen Treiber, um die Daten an den virtuellen Hardware-Adapter der Virtualisierung weiterzuleiten. Dieser virtuelle Hardware-Adapter leitet es dann an das Filesystem der Virtualisierung (beim VMware ist es das VMFS oder vSAN, bei Proxmox z.B. ZFS oder Ceph, bei Hyper-V zum Beispiel NTFS) weiter. Vom Filesystem (oder einem virtuellen Blockdevice) geht es dann über den Treiber zum physikalischen Speicheradapter weiter. Dieser ist entweder über das Speichernetzwerk an das RAID-System angeschlossen (Shared Storage) oder lokal an einem RAID-Controller. Auch beim Speichernetzwerk (zum Beispiel Fibre Channel oder iSCSI) gibt es noch Optimierungsmöglichkeiten. Im externen RAID-System ist ein Cache vorhanden und über einen RAID-Level geht es auf die Platten. Je nach RAID-Level und Möglichkeiten des RAID-Controllers sind unterschiedlichen Stipe-Sizes möglich. Und bei den Festplatten ist auch noch eine große Auswahl (SAS-Platten oder SATA, oder SSDs) vorhanden, mit unterschiedlichen Vor- und Nachteilen. In dieser Kette sind viele Faktoren vorhanden, die zum größten Teil auch noch untereinander abhängig sind.
Nachfolgenden finden Sie zwei Beispiele für das Performance Tuning im Storage-Bereich. Dies gilt nicht nur alleine für die Virtualisierung, auch bei großen und performanten Anwendungen auf einem physikalischen Server kann ein Tuning einiges an Verbesserungen bringen.
Entscheidend bei Ceph ist die Anzahl der OSDs. Ein OSD (Object Storage Daemon) ist der Prozess auf dem Ceph System,
der für die Speicherung der Daten zuständig ist. Je mehr OSD Prozesse vorhanden sind, desto mehr IO Operationen können
parallel verarbeitet werden. Proxmox schlägt einen OSD pro Storage Device vor. Wenn also im Node 5 SSDs oder NVMe vorhanden sind, dann werden auch 5 OSDs
gestartet bzw. genutzt. Allerdings verbrauchen OSDs auch RAM und CPU, das muss beachtet werden.
Und natürlich die Anzahl der Nodes im Ceph Cluster. Je mehr Nodes, desto besser können IOs verteilt werden. Also ein weiterer Node im System
kann nicht nur den Speicherplatz erhöhen, sondern auch die Performance verbessern.
Also vieles, was die Performance verbessern kann. Aber wichtig ist auch die Sicherheit, also sollen zum Beispiel die Daten auf einem 3 Node-Cluster
auf allen 3 Nodes vorhanden sein. Das verschlechtert die Performance aber, da die Daten je erst auf allen Nodes angekommen sein müssen, bevor der
Client (also die VM) einen Write-OK bekommt. Aber eine gewisse Redundanz muss ja vorhanden sein.
Ein großer Faktor ist auch das Netzwerk zwischen den Nodes für die Ceph Zugriffe und Replikationen:
- Es sollte ein eigenes Netzwerk sein
- Es sollte mindestens 10 Gbit/s nutzen, besser 25 Gbit/s Ethernet
- Es sollte redundant aufgebaut sein
- Bei 3 Nodes kann es auch Direct Attached ohne Switch aufgebaut werden
Zur Überprüfung der Performance bietet Ceph einige Tools an. Mit "rados bench" kann ein Pool mit einer bestimmten Blocksize und einer Anzahl
von parallelen Threads getestet werden. Die Tests sind für Schreib- und Lese-Operationen möglich. Wichtig aber bei diesen Messungen sind die Anzahl
der parallel ausgeführten Befehle. Ein einzelner losgelöster Befehl wird selten einen realistischen Wert ermitteln. Selbst im Vergleich zu anderen
Clustern ist nur ein Befehl nicht aussagekräftig.
Viele denken jetzt: Das ist aber Trivial, was soll ich schon bei den Blöcken, also der Blocksize von Filesystem und RAID machen? Da nehme ich immer die Default-Werte und gut ist ... Aber warum nehmen wirklich so viele Administratoren die Default-Werte? Wenn man etwas ändern oder anpassen möchte, muss man auch wissen warum man etwas ändern muss und welches die richtige Änderung ist (kleiner oder größer oder alles gleich). Und genau in diesem Punkt wird es sehr schwierig. Aber schauen wir uns erst mal die Grundlagen in einem Beispiel an. In der Übertragungskette gibt es sehr viele verschiedene Blöcke in verschiedener Blocksize und Anordnung in den einzelnen Schichten. Vom Betriebssystem der VM wird ein bestimmter Block im NTFS angesprochen, der liegt in einem oder mehreren Blöcken im Filesystem der Virtualisierungsschicht. Diese Blöcke liegen wiederum auf einem RAID-System und werden über ein Netzwerk (FC oder iSCSI), auch in Blöcken, transportiert.
Schauen wir uns mal ein ungünstiges Beispiel an:

Die Blöcke starten immer am Anfang (so ist der Default) und es werden auch die Default Werte bei den Blöcken genutzt. Greift in unserem ersten Beispiel jetzt in der VM eine Anwendung auf einen einzelnen Block im NTFS zu, so müssen schon 3 Blöcke aus dem RAID-Set gelesen werden. Haben wir beispielsweise eine Stripe-Size von 256 kB eingestellt, so müssen wir trotzdem 768 kB lesen, also das Dreifache. Sind wir in diesem Fall am Limit des RAID-Controllers oder des Übertragungsmediums angekommen, so könnte durch die Optimierung der 3fache Durchsatz für die VM erzielt werden.
Jetzt ein wesentlich besser optimiertes Beispiel. Es wird pro benötigten Block in der VM am wenigsten Daten übertragen, die Startpunkte der jeweiligen Systeme sind aufeinander abgestimmt worden:

Benötigt jetzt eine Anwendung in der VM einen Block, so muss genau ein Block aus dem VMFS und ein entsprechender Block aus dem RAID gelesen werden. Wichtig ist bei dieser Optimierung, dass der Startpunkt der Blöcke für VMFS und NTFS jeweils soweit nach innen verschoben wird, das die Grenzen übereinander liegen. Wird dies nicht gemacht, so müssen dann zwei VMFS-Blöcke und mindestens 3 Stripe-Blöcke gelesen werden.
Es sind jetzt verschiedene Varianten denkbar. Wenn zum Beispiel immer viele NTFS Blöcke hintereinander gelesen werden müssen (sequentielle Daten), dann können auch mehr NTFS-Blöcke in einem VMFS-Block liegen, bzw. mehrere VMFS-Blöcke in einem Stripe. Da wird es aber schon wieder schwieriger. Sind jetzt ein Fileserver mit großen Daten und ein Datenbankserver mit kleiner Blocksize auf einem Storage-System (bzw. in einer Virtualisierung) untergebracht, so behindern sich die Optimierungen gegenseitig. Da bleibt eigentlich nur noch ein individueller Test, welche Optimierung bzw. welcher Kompromiss für alle Systeme am besten ist.
Lange Rede: Was ist jetzt in der Praxis? Bei VMware (ab der Version ESXi 5.0) ist es normalerweise so, dass beim Anlegen des VMFS Filesystems oder der VMDK Datei über die GUI, diese schon automatisch ausrichtet werden. Es sollte also nur in Ausnahmefällen die CLI genutzt werden. Aber auch wenn die VMFS Volumes schon mit Versionen vor ESXI 5.0 angelegt wurden, kann ein Neuanlegen (zum Beispiel bei einer Migration) die Performance verbessern. Dazu müssen aber die Daten vorher verschoben werden.
Besteht das Storage-Netzwerk in einer virtuellen Umgebung aus iSCSI-Komponenten, so sind vielfältige Tuning-Möglichkeiten vorhanden. Auch hier muss erst einmal analysiert werden, wo denn das Nadelöhr ist. Ein einfaches Beispiel: Die CPU in der Hardware ist sehr stark belastet und die VMs verursachen nicht die gesamte Last. Dies könnte durchaus vom Software-iSCSI-Initiator kommen. Bei der iSCSI-Software-Lösung wird die gesamte Verpackung und Entpackung der iSCSI Pakete durch die CPU erledigt. Also je mehr I/O, desto mehr CPU Belastung. Eine einfache Abhilfe sind Netzwerkkarten mit TCP Offload Engine (TOE) oder iSCSI HBAs. Auf den Karten sind eigene Prozessoren enthalten, die die Verpackung der Pakete übernehmen.
Ist aber die Datenübertragung bei iSCSI an sich zu langsam, so kann auch dies noch verbessert werden. Im iSCSI (und TCP) gibt es einige Einstellmöglichkeiten, die die Performance beeinflussen. Leider gibt es keine allgemeingültigen Parameter für optionale Ergebnisse. Als Beispiel haben wir einen VMware ESX 4 Server mit einem Open-E iSCSI System als Storage betrachtet. VMware, wie auch Open-E geben einige Parameter an, die vom Default geändert werden sollen:
MaxRecvDataSegmentLength=262144
MaxBurstLength=16776192
Maxxmitdatasegment=262144
Maxoutstandingr2t=8
InitialR2T=No
ImmediateData=Yes
Diese Werte lassen sich im ESX Server über die erweiterten Einstellungen
der iSCSI Ports bzw. im Storage-System über das jeweilige Target einstellen.
Wie schon gesagt, sind dies nicht unbedingt für jede Umgebung die idealen
Werte. Evtl. muss da individuell getestet und verglichen werden. Auch das obige
Thema mit den Blöcken spielt in dieses Thema rein und vereinfacht es nicht
gerade. Sind die optionalen Blöcke im Filesystem und auf dem RAID ein klein
wenig zu groß für die iSCSI Blöcke, so bringt die Optimierung
im Filesystem unter Umständen überhaupt nichts.
Werden in einer virtuellen Umgebung Performanceprobleme festgestellt, so ist die Analyse erst
mal recht undurchsichtig. Wo liegt jetzt das eigentliche Problem? Nehmen wir einmal VMware vSphere als
Beispiel. Wenn dort die Antwortzeiten von Anwendungen und Applikationen schlecht sind, dann
gibt es viele Analysemöglichkeiten. Der zentrale Ansatz ist auf jeden Fall der ESXi. Und der
bringt auch einige Möglichkeiten zur Fehlersuche mit. Dies ist einmal die grafische Aufbereitung
der Performancedaten. Hier lassen sich schon viele Probleme erkennen. Ist die CPU Auslastung
über einen langen Zeitraum recht hoch für den Server, dann kann auf die einzelnen virtuellen Maschinen
geschaut werden, welche zu viel CPU verbraucht. Hier kann man auch recht schnell entscheiden ob der
CPU Verbrauch einer VM richtig ist, oder ob schon dort der Fehler vorliegt. Ähnlich kann auch
mit dem RAM verfahren werden. Dort ist die Lösung meist recht einfach, wenn an sich keine
Störung vorliegt, es wird einfach mehr RAM eingebaut, oder eine VM wird verschoben.
Problematischer wird die Fehlersuche meist bei den Datenspeichern. Auch hier bietet VMware viele
grafische Auswertung an, jedoch sind diese immer zeitlich gemittelt. Kleine Peaks werden meist
nicht erkannt und komplexe Zusammenhänge werden grafisch meist wegen Unübersichtlichkeit nicht erkannt.
Hier hilft das Texttool esxtop direkt auf der Console des ESXi. Es ist dem üblichen top von Linux
nachempfunden und zeigt detailliert die Zustände im ESXi an. Neben CPU und RAM werden die Devices und Units
ausgewertet, aber auch die virtuellen Maschinen. Durch eine einstellbare Aktualisierungsrate können auch kleine
Peaks noch erkannt werden.
Beispiel esxtop für Devices:
6:51:15pm up 13 days 1:41, 326 worlds, 3 VMs, 4 vCPUs; CPU load average: 0.11, 0.14, 0.14
| ADAPTR | PATH | NPTH | CMDS/s | READS/s | WRITES/s | MBREAD/s | MBWRTN/s | DAVG/cmd | KAVG/cmd | GAVG/cmd | QAVG/cmd |
| vmhba0 | - | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| vmhba1 | - | 2 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.76 | 0.01 | 0.77 | 0.00 |
| vmhba32 | - | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| vmhba33 | - | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| vmhba34 | - | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| vmhba35 | - | 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| vmhba36 | - | 1 | 2.81 | 0.00 | 2.81 | 0.00 | 0.01 | 1.53 | 0.01 | 1.54 | 0.00 |
Hier können Basisdaten wie zum Beispiel die Reads oder Writes pro Sekunde oder die Übertragungsrate
getrennt nach Read und Write ermittelt werden. Bei diesen Werten gibt es kein "Gut" oder "Schlecht",
eher ein "sinnvoll" oder ein "nicht nachvollziehbar". Es kommt immer auf die Umgebung an, große Datenbanken
können auch sehr viele Lese- oder Schreiboperationen verursachen, ohne dass es eine Störung ist. Diese Werte
müssen immer von Fall zu Fall abgeglichen werden. Interessant sind mehr die DAVG/cmd und die KAVG/cmd, beide Werte
zeigen die Antwortzeit. Liegt zum Beispiel die DAVG über 25, so wird das meist als kritisch eingestuft. Die KAVG Werte über
3 deuten auf Probleme im Kernel hin, zum Beispiel eine fehlerhafte Failover Policy oder eine falsche Queue Depth.
Insgesamt muss das System und auch die ganze Umgebung genau analysiert werden, esxtop kann aber als erste Anlaufstelle
zur Ermittlung der Fehlerursache genutzt werden.

Für Virtualisierungsprojekte bieten wir die passenden Storage-Lösungen an, setzen Sie sich mit uns in Verbindung. Natürlich können Sie auch komplette Lösungen von uns bekommen. Egal zu welcher Virtualisierungssoftware, wir finden ein für Sie passendes Storagesystem.